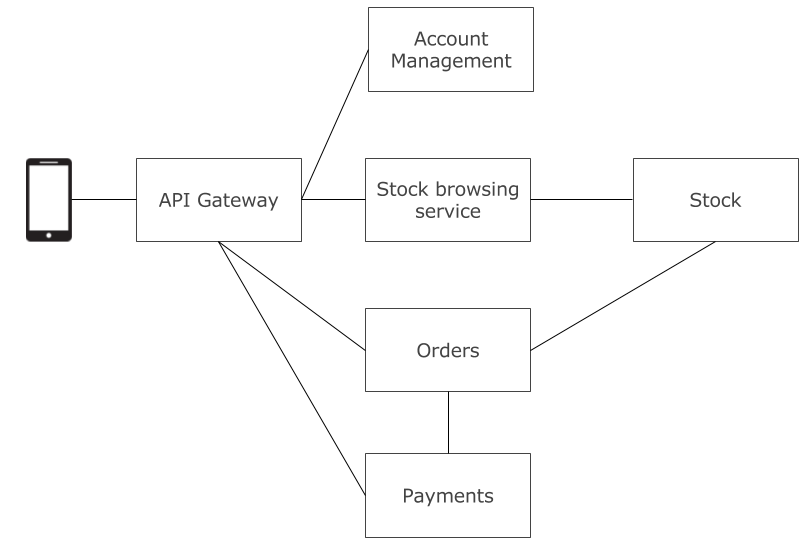
Jednym z pierwszych wyzwań stojących przed mikroserwisami jest wybór sposobu komunikacji.

Wybór rodzaju interakcji
Wybierając odpowiedni w danym przypadku styl interakcji musimy zbadać jakiego rodzaju komunikacją mamy do czynienia. Mamy tutaj do wyboru:
- Jeden do jednego – inicjator wykonuje żądanie, które jest przetwarzane przez dokładnie jeden serwis odbierający żądanie
- Jeden do wielu – w tym modelu wiadomość może być przetwarzana przez wiele serwisów odbierających (w szczególnym wypadku może być to jeden lub zero serwisów). Zazwyczaj dla serwisu inicjującego konwersacje, będzie transparentne to ile serwisów przetwarza to żądanie
Styl interakcji
Wybór stylu interakcji sprowadza się do pytania czy komunikacja ma charakter synchroniczny czy asynchroniczny:
- Komunikacja synchroniczna – inicjator czeka na odpowiedź
- Komunikacja asynchroniczna – inicjator nie czeka na odpowiedź
 source:Photo by Tony Stoddard on Unsplash
source:Photo by Tony Stoddard on Unsplash
Najpopularniejszymi wzorcami interakcji są:
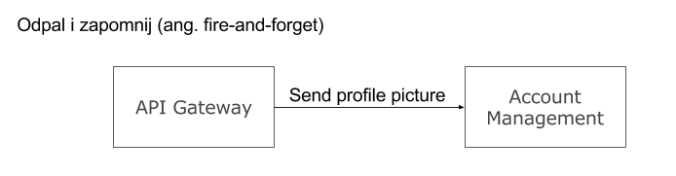
- Odpal i zapomnij (ang. fire-and-forget) – inicjator konwersacji wysyła wiadomość, która dociera do odbiorcy. I to w zasadzie tyle. Ciężko sobie wyobraźić prostszy schemat konwersacji.
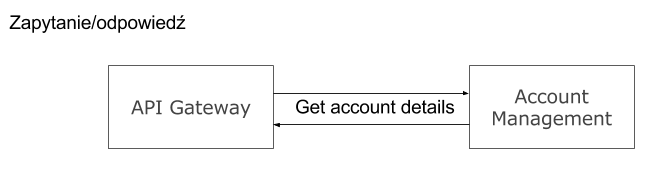
- Zapytanie/odpowiedź – najczęściej stosowana metoda interakcji. Strona inicjująca odpytuje drugą i czeka na odpowiedź, która powinna pojawić się w określonym czasie.
- Zapytanie/asynchroniczna odpowiedź – polega na wysłaniu zapytania przez klienta do serwisu, który odpowiada asynchronicznie. Jakie ma to implikacje? Otóż klient może w sposób nieblokujący czekać na odpowiedź. Nic nie stoi na przeszkodzie by w tym czasie robić inne obliczenia. Do klienta należy obsługa całkiem prawdopodobnej sytuacji, iż takiej odpowiedź nie dojdzie.

- Publikacja/subskrypcja – przesyłanie wiadomości polega tutaj na udostępnianiu informacji przez publikatorów, a ich odbiorcami są wszystkie jednostki w systemie, które są zainteresowane danym komunikatem.

Technikalia
Posiadając do wyboru kilka możliwych wzorców interakcji musimy zdecydować się jeszcze na techniczne szczegóły co do sposobu w jaki taka interakcja zostanie zrealizowana.
By zapewnić jak najlepszą niezawodność systemu przy wysokiej wydajności i skalowalności, najczęściej najlepszym wyborem będzie kombinacja technologii komunikacji. W różnych miejscach systemu możemy zastosować różne sposoby komunikacji:
- HTTP/REST API
- Wiadomości (messaging)
- Inny, specyficzny dla domeny protokół komunikacji
W zależności od tego który ze sposobów komunikacji wybierzemy musimy liczyć się z konsekwencjami. I tak:
1. HTTP/REST API
 Source:Photo by Pavan Trikutam on Unsplash
Source:Photo by Pavan Trikutam on Unsplash
Szybki, elastyczny sposób na implementację komunikacji pomiędzy serwisami. Dla większości programistów będzie to także po prostu najprostsze w użyciu narzędzie. Często wykorzystywany do wykonywania zapytań (w odróżnieniu do komend). Dużym plusem jest brak narzutu co do konkretnej technologii. Serwisy wykorzystujące komunikację poprzez HTTP/REST API mogą korzystać z szerokiej gamy rozwiązań. Co najważniejsze, nie ma problemu by po obu stronach komunikacji występowały całkowicie różne technologie.
Ta technologia, w najprostszej wersji, charakteryzuje się synchronicznością działania co w zależności od kontekstu będzie zaletą bądź też wadą. Dzięki powszechnej znajomości tego rozwiązania zazwyczaj nie będzie problemu z zastosowaniem tego rozwiązania. Definitywnym minusem tego rozwiązania jest wrażliwość na problemy z dostępem do sieci, w chwili wykonywania zapytania obie strony interakcji muszą działać. Inną wadą jest wymaganie znajomości adresu serwisu przez klienta. Intuicyjnie może to nie wydawać się jak duży problem, aczkolwiek skalowanie systemu wymaga od nas by klient mógł i wiedział jak może połączyć się z wszystkimi instancjami danego serwisu.
2. Wiadomości (messaging)

Wymiana informacji pomiędzy serwisami za pomocą wiadomości to świetny sposób na rozluźnienie powiązania pomiędzy nimi. Ta, z natury asynchroniczna, komunikacja polega na tym, że jedna ze stron komunikacji zapisuje wiadomość, natomiast druga ją odczytuje. Dobrze to współgra z wzorcami architektonicznymi takimi jak CQRS i EDD (Event-Driven Development). Decydując się na ten sposób komunikacji, musimy podjąć decyzję jakiej technologii użyjemy. Przykładowymi, popularnymi rozwiązaniami są: Apache Kafka, AWS Kinesis Streams, Azure Service Bus, RabbitMQ, NServiceBus, MassTransit, MSMQ. Wspomniane rozwiązania różnią się znacznie podejściem do architektury systemu, poziomem abstrakcji i sam opis tychże różnic to spory temat. Dodatkowo mamy tutaj spory wachlarz wzorców komunikacji jak np. : publikacja/subskrypcja czy też zapytanie/odpowiedź. Możemy tutaj uzyskać wysoką skalowalność jak i wysoką dostępność systemu za cenę dodatowej złożoności systemu spowodowanej wykorzystaniem infrastruktury umożliwiającej komunikację przez wiadomości.
3. Specyficzny protokół komunikacji taki przesył danych binarnych, JSON czy też XML.
Czasami sytuacja zmusza lub też zachęca nas do użycia jakiegoś innego formatu danych. Często jest to uwarunkowane specyficznymi wymaganiami w konkretnej domenie i umożliwia to np. wydajny streaming multimediów.
Komunikacja między serwisami wymaga od nas znajomości charakteru interakcji co potem wpływa na wybór technologii. Każda z tych decyzji niesie za sobą zalety ale i wady, ale mając ich świadomość jesteśmy w stanie zbudować system, który w wydajny sposób się komunikuje i wykorzystuje infrastrukturę by uzyskać zarówno wysoką dostępność jak i niezawodność.
Bibliografia i inne ciekawe materiały: