Pomysł
Nie zawsze twój komputer jest na tyle wydajną maszyną by było to dla ciebie wygodne środowisko programistyczne. Czasami zdarza się tak, że trzeba sięgnąć jednak po coś szybszego. Nie zawsze chcesz kupować nowy komputer tylko na potrzeby jednego projektu, prawda? Niezależnie od powodów zakładamy, że skoro czytasz ten wpis to chcesz zająć się uczeniem maszynowym z Tensorflow na EC2 czyli AWSowym serwisem – Elastic Compute Cloud. Co więcej, będziemy chcieli by dostęp do systemu odbywać się przez GUI co daje o wiele większe pole manewru przy Machine Learning, który przecież może dotykać każdego medium, czy to tekst, dźwięk, obraz czy wideo.

Pisałem o Tensorflow, ale w niemalże identyczny sposób możesz wykorzystać EC2 do programowania przy użyciu innych popularnych bibliotek, takich jak:
- PyTorch
- Apache MXNet
- Chainer
- Microsoft Cognitive Toolkit
- Gluon
- Horovod
- Keras
(aktualna lista https://aws.amazon.com/machine-learning/amis/)

Warunki wstępne
Założenie konta nie powinno sprawić ci większych trudności. AWS dość dobrze i dokładnie tłumaczy jak to zrobić. Jeżeli dopiero teraz zakładasz konto, na pocieszenie pamiętaj o wykorzystaniu bonusów z AWS Free Tier https://aws.amazon.com/free/ . Jest to na prawdę ciekawa możliwość na przetestowanie wielu serwisów AWS-a przez pierwszy rok za darmo (a niektórych nawet dłużej niż rok). Oczywiście to ‚testowanie’ jest poddane ograniczeniom jednak często w zupełności wystarcza do stworzenia prostych serwisów.
Ale teraz do meritum.

Pierwsze kroki
Zakładając, że masz już konto na AWS. Możemy przejść do ciekawszych spraw.
W konsoli AWS, przechodzimy do serwisu EC2 i tworzymy nową instancję. Jaki region wybrać? Proponuje Frankfurt ew. Irlandia (prawy górny róg).

Przechodzimy do uruchamiania instancji.

Naszym oczom ukazuje się obraz wyboru obrazu, którego chcemy użyć. Wybieramy odpowiedni AMI, czyli Amazon Machine Image. Wpisujemy w pole wyszukiwania ‚Deep Learning’. To specjalnie przygotowane obrazy z narzędziami do Machine Learning jak np. tytułowy Tensorflow. Oczywiście moglibyśmy zainstalować wszystko od zera. Moglibyśmy też kupić sobie maszynkę i nie używać chmury itd… 🙂 W każdym razie, powinniśmy zobaczyć ekran:
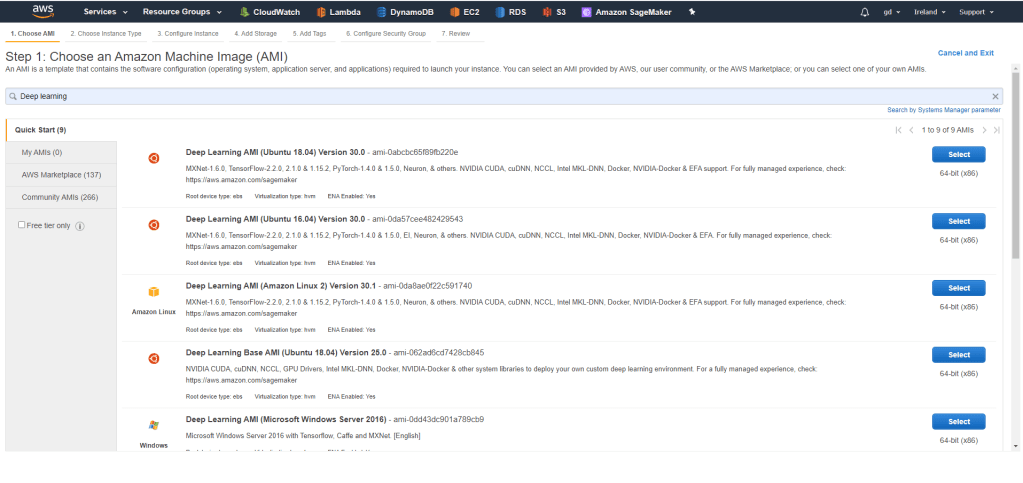
Ja np. wybrałem maszynkę z najnowszym Ubuntu i jeżeli nie masz swoich preferencji to wybierz ją także.
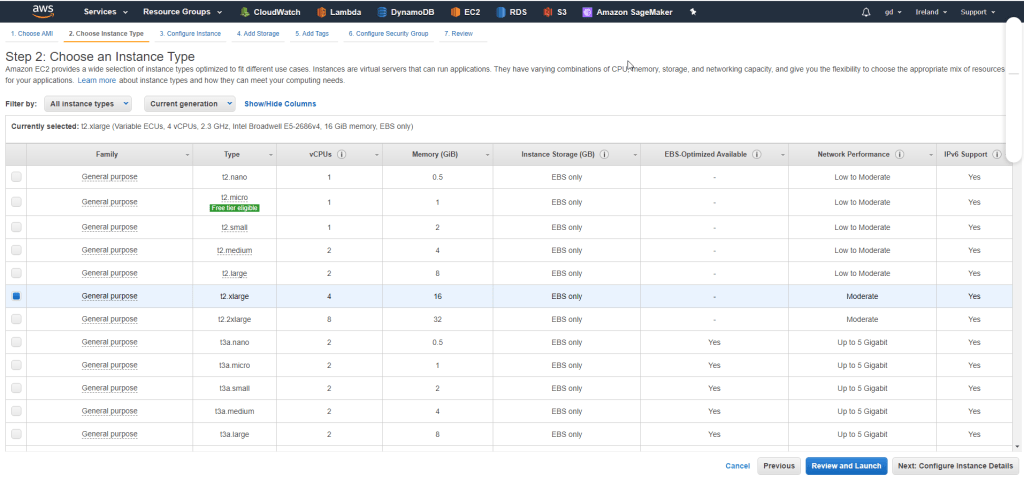
Rodzaj instancji
Kuszące może być skorzystanie z wersji ‚micro’ by wykorzystać ww. Free Tier. Jednak szczerze to odradzam tego rodzaju skąpstwo. Używamy AWS gdyż zapewnia nam wygodne skalowanie maszyny do problemu, ale na maszynie ‚micro’ raczej nie rozwiążemy żadnego problemu. Na początek możesz wybrać np. t2.xlarge. Jest to instancja generalnego przeznaczenia i traktujemy ją jak playground. Później w każdej chwili możemy przesiąść się na coś bardziej dedykowanego pod Machine Learning.
Pamiętaj, żeby przed użyciem maszyny zapoznać się z cennikiem, tak żeby nie było, że nie uprzedzałem https://aws.amazon.com/ec2/pricing/
Warto nadmienić, że w następnym wpisie mogę pokazać ci jak znacząco ograniczyć koszta poprzez wykorzystanie tzw. ‚spot instances’ jednak tutaj nie chcę nadmiernie komplikować rozwiązania.
Klikamy kolejno na ‚Review and Launch’
I potem ‚Launch’
Credentials
Dobrą praktyką będzie stworzenie osobnych kluczy, wybieramy ‚Create a new pair’
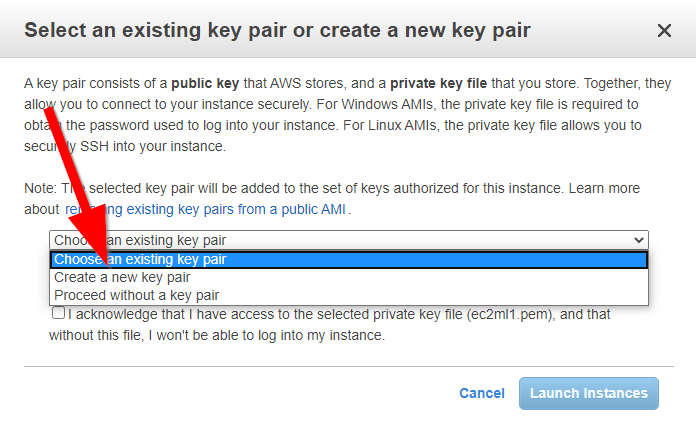
Jeżeli teraz spróbujemy użyć kluczy, możemy napotkać na problem z kompatybilnością ich formatu. Jeżeli tak się stanie, a dla mnie się to stało, to będziemy potrzebować aplikacji putty https://www.putty.org/ więc proszę ściągnij ją. Odpalamy narzędzie puttygen.exe przychodzące w zestawie z putty i ładujemy klucz ściągnięty z AWSa.
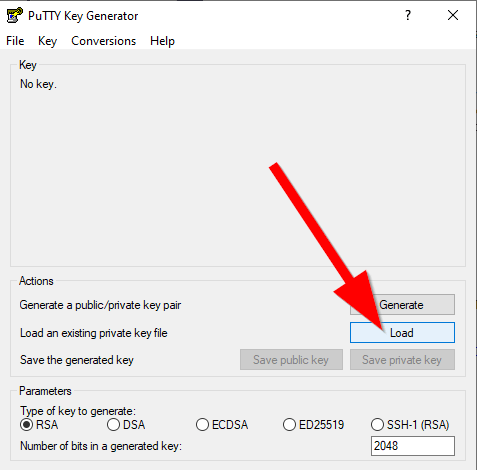
I zapisujemy w formacie ppk. Uff mamy klucz do drzwi. Ale gdzie są drzwi???!
Wracamy do naszej świeżo wypieczonej instancji EC2. Na stronie z instancjami EC2 mamy na dole panel ze szczegółami dotyczącymi naszej instancji. Nas przede wszystkim interesuje adres publiczny IP i adres prywatny IP. To przez te adresy spróbujemy połączyć się z naszego komputera do instancji.
Putty
Tak, zwracamy się o pomoc do Pana Putty.
Naszym oczom ukazuje się ekran niczym z … dobra nie hejtujmy, putty to na prawdę świetne rozwiązanie.
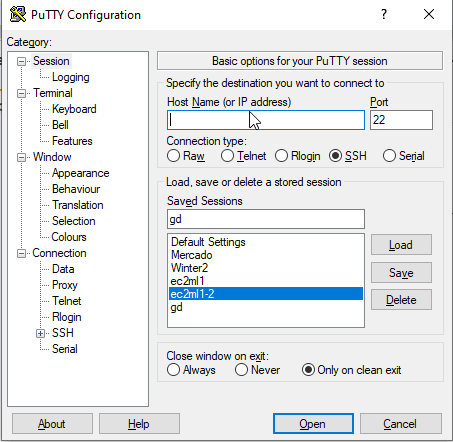
w pole Host Name wpisujemy nasz publiczny adres i przechodzimy do Connection>SSH>Auth i klikamy Browse wybrać klucz który uprzednio skonwertowaliśmy

Teraz otwieramy zakładkę ‚Tunnel’ i tworzymy tunel do naszej instancji, jako port źródłowy podajemy dowolny wolny port, u mnie np. 8080 i jako cel tunelu: prywatne IP instancji EC2 oraz port 3389. Dzięki temu ruch na nasz localhost:8080 zostanie przekierowany przez Putty do AWS do naszej prywatnej maszynki przez port 22 na adres prywatny i port 3389 (RDP).
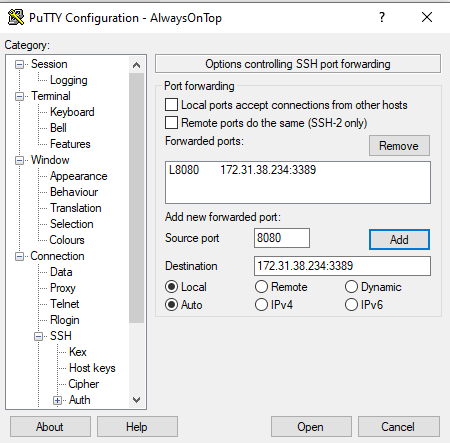
Ważna sprawa, po każdej zmianie zapisujemy sesję, by nie stracić dotychczasowego nakładu pracy:
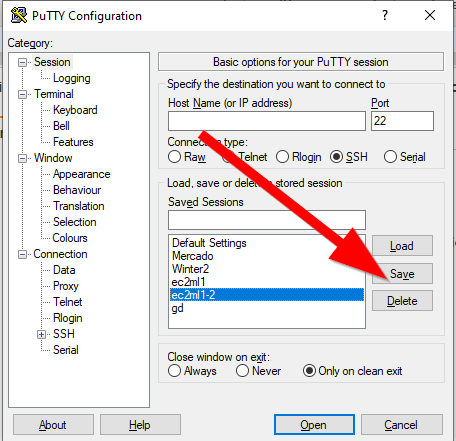
Dobra ale nasza instancja nie jest jeszcze gotowa by pokazać swój desktop. By ją do tego przygotować otwieramy naszą sesję (Open) i pokaże nam się okno w stylu:
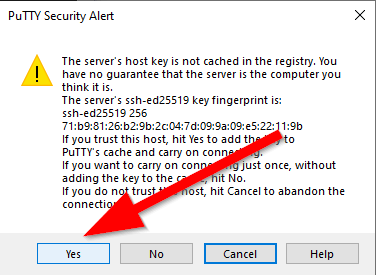
Przy pierwszym połączeniu jest to oczekiwany rezultat. Przechodzimy dalej klikając Yes.
Na następnym ekranie wita nas już terminal naszego systemu. Login to: ubuntu
Jeżeli widzisz ekran taki jak
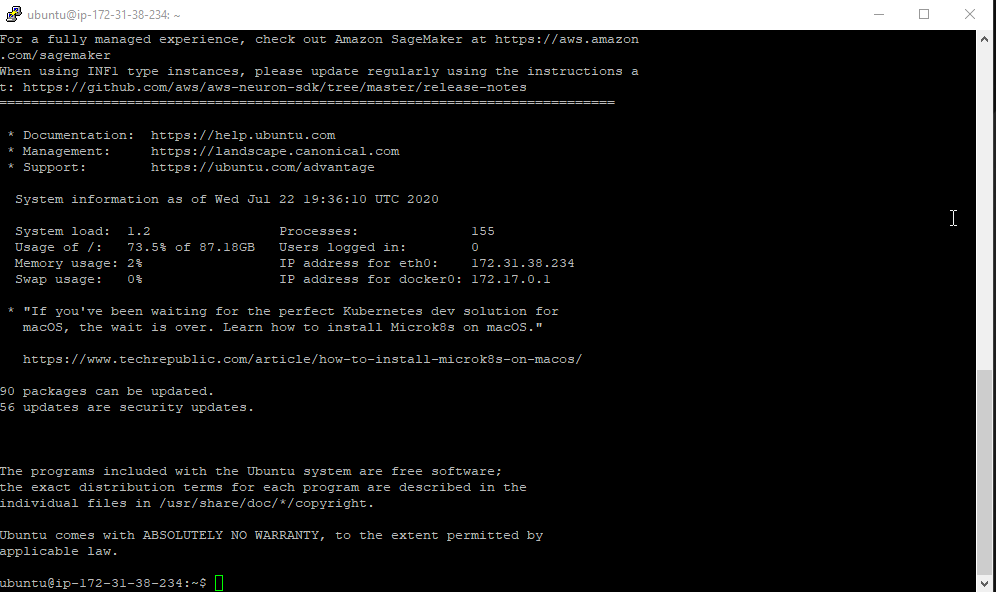
to brawo, udało się, jesteśmy połączeni. Teraz możemy przystosować naszą instancję by umożliwić tryb GUI.
Pamiętaj żeby zachować hasło, które podasz za chwilę, w przeciwnym wypadku połączenie będzie niemożliwe.
sudo apt update && sudo apt upgrade
sudo sed -i 's/^PasswordAuthentication no/PasswordAuthentication yes/' /etc/ssh/sshd_config
sudo /etc/init.d/ssh restart
sudo passwd ubuntu
sudo apt install xrdp xfce4 xfce4-goodies tightvncserver
echo xfce4-session> /home/ubuntu/.xsession
sudo cp /home/ubuntu/.xsession /etc/skel
sudo sed -i '0,/-1/s//ask-1/' /etc/xrdp/xrdp.ini
sudo service xrdp restartźródło powyższego skryptu: youtube https://www.youtube.com/watch?v=6x_okhl_CF4
Po wykonaniu powyższych instrukcji przystępujemy do ostatniego etapu. Uruchamiamy Remote Desktop Connection (RDP) i podajemy adres localhost:8080 (lub jakikolwiek inny port skonfigurowany w putty)
Mamy to! Tryb GUI na AWS EC2!
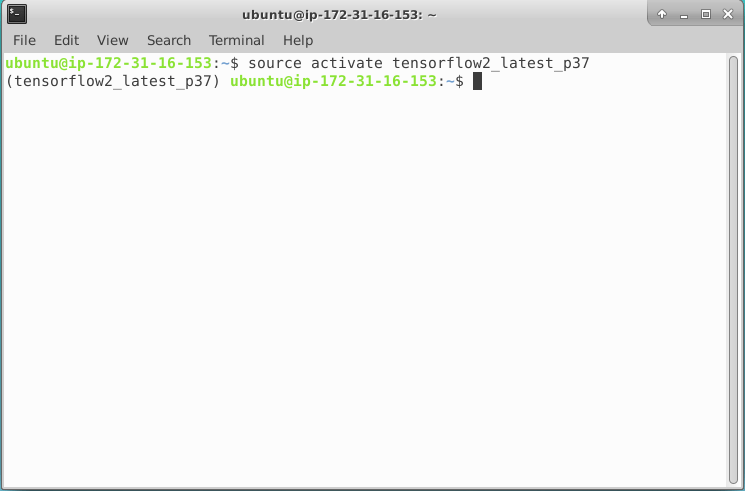
Jeszcze tylko włączmy odpowiednie środowiko uczenia maszynowego i jesteśmy w domu. Przebyliśmy dziś długą drogę, ale na szczęście aktywacja Tensforflow na naszej maszynie będzie bardzo prosta dzięki obrazowi (AMI), który wybraliśmy (Deap learning).
Wykorzystujemy najnowszą wersję Tensorflow przy użyciu:
source activate tensorflow2_latest_p37i w konsoli możemy już zaczynać pracę.
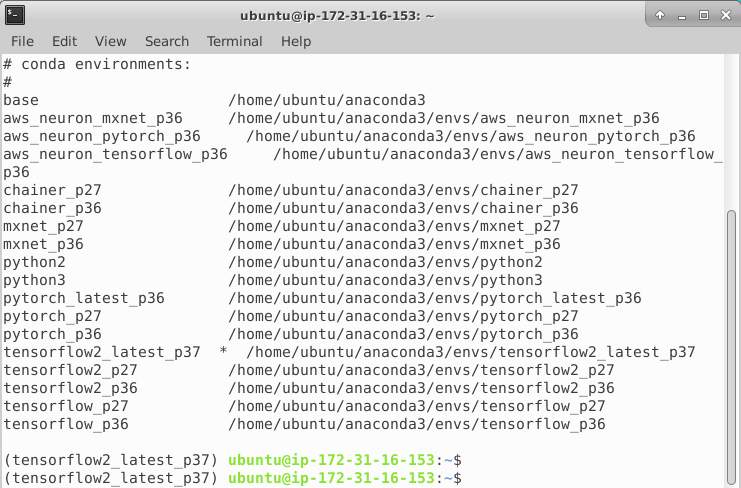
Jeżeli wolisz jakąś inną wersję Tensorflow-a, bądź też całkiem inny pre-instalowany framework, zawsze możesz wykorzystać komendę listującą dostępne środowiska i wybrać coś innego:
Po wyborze i aktywacji odpowiedniego środowiska możemy przetestować, że wszystko poszło po naszej myśli. W moim wypadku w konsoli python-a wpisuję:
import tensorflow
print(tensorflow.__version__)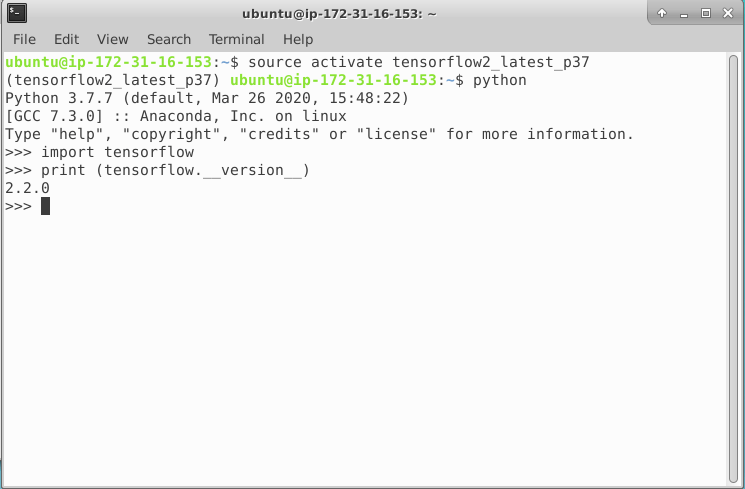
Wszystko gra. Przed nami otwierają się nowe możliwości.
Aha, no i przypominam, że z wykorzystaniem AWSa wiążą się koszty, czasami całkiem konkretne, zapoznaj się z cennikiem https://aws.amazon.com/ec2/pricing/, po skończonej pracy wyłączaj maszyny, używaj spot instances, minimalizuj wykorzystane volumes i generalnie czytaj cenniki rzeczy których używasz i trzymaj rękę na pulsie przez umieszczenie alarmów na wykorzystane środki na AWS
Linki: