Zapomnijmy na chwilę o mikroserwisach pomimo, że mowa o nich w tytule. Wyobraźmy sobie serwer udostępniający dane o użytkownikach pewnego portalu społecznościowego. Niech będą to szczegółowe dane takie jak imię, nazwisko, ale i ostatnie aktywności na portalu czy też opublikowane posty. Taki serwer udostępnia pewnie jakieś API do pobierania tych informacji zgromadzonych w bazie danych. Powiedzmy, że mamy metodę GetPerson(), która to wykorzystując warstwę aplikacyjną odpytuje repozytoria o dane osoby z innej tabeli wczytujemy ostatnie aktywności a jeszcze z innej ostatnie posty użytkownika. W tej sytuacji aplikacyjna kliencka odpytuje nasze API, odpowiednio prezentuje dane i mamy to.

Problemy rozproszonej lokalizacji zasobów
Wróćmy do mikroserwisów. Sytuacja nieco komplikuje się, bo dane interesujące aplikacje klienckie są rozsiane po różnych zakamarkach systemu. W ostateczności moglibyśmy w końcu dociec gdzie co jest zlokalizowane, w jakim formacie musimy odpytać dany mikroserwis (albo zmusić wszystkie do wystawiania Rest API itd.), ale rodzi to wiele problemów:
- Co z uwierzytelnianiem? Czy każdy mikroserwis musi się tym przejmować?
- Jak zminimalizować wpływ zmian w strukturze i funkcjonalności mikroserwisów na działanie klientów?
- Co ze skalowaniem? Co jeżeli zwiększamy liczbę instancji danego serwisu? Kto decyduje o adresie docelowym zapytania?
- Załóżmy, że zmieniamy odpowiedzialności mikroserwisów, wprowadzamy nowe, usuwamy stare. Jakkolwiek zmieniamy wewnętrzną strukturę systemu. Jak wyeliminować zmiany po stronie klientów API?
Rozwiązanie
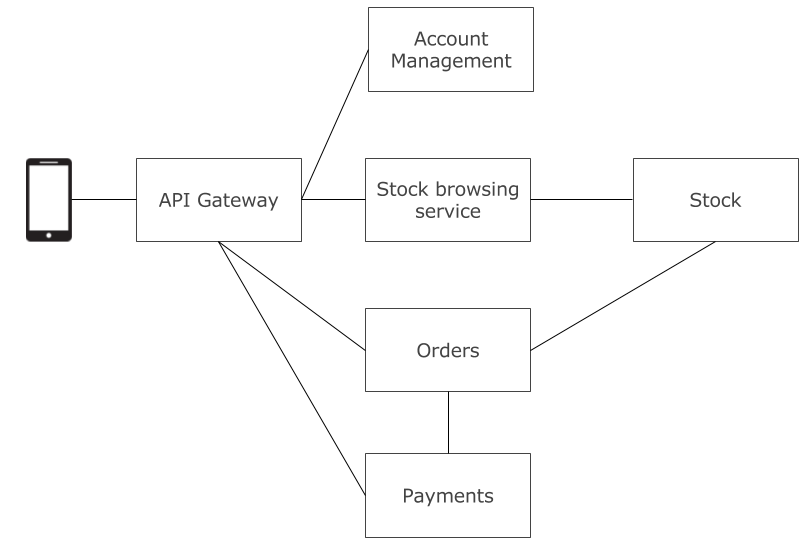
Jak można się tego spodziewać istnieje rozwiązanie, które upraszcza większość z problemów, które mogą się pojawić w kontekście interakcji między klientem a serwerem w architekturze mikroserwisów. Możemy wprowadzić dodatkowy komponent pośredni między warstwą aplikcji, a aplikacją kliencką, a jest nim API Gateway.
API Gateway to pewien rodzaj reverse proxy. Jego rolą jest odizolowanie reszty mikroserwisów od kwesti związanych z obsługą zapytań z aplikacji klienckich, a więc będzie on przekierowywał zapytania z klienta do odpowiednich serwisów. Odnosząc się do analogii z tytułu posta, API Gateway to drzwi wejściowe do naszego systemu. Z punku widzenia aplikacji klienckiej wszystko za tymi drzwiami jest ukryte i jeżeli nie podamy jej czegoś przez te drzwi to tego nie dostanie. Nie pozwalamy na wejście oknami czy też przez balkon.
Zalety
Co dzięki temu zyskujemy?
- Klient nie troszczy się ani o lokalizację mikroserwisów, ani o to w którym mikroserwisie zlokalizowany jest interesujący go zasób, ani o to ile instancji danego mikroserwisu jest dostęne, ani o to czy zmienimy strukturę mikroserwisów, ba, on nie troszczy się o to czy ma doczynienia z mikroserwisami w ogóle!
- Umożliwiamy odpytywanie systemu przez wygodne API, które może być dostosowanie API pod konkretnych klientów, bez konieczności implementacji tego w każdym mikroserwisie.
- Mamy tylko jeden punkt w którym uwierzytelniamy użytkownika.
- Możemy łączyć, filtrować, sortować i w różny sposób manipulować danymi w taki sposób by dostosować je do oczekiwań aplikacji klienckiej.
- Pozwalamy mikroserwisom rozmawiać między sobą w formacie, który jest dla nich wygodny, ponieważ nie ma to wpływu na klienta
- Możemy wersjonować API wystawione przez nasz Gateway w jeden sposób, a API wewnętrzne wykorzystywane przez mikroserwisy w naszym systemie w całkowicie inny sposób.
- Łatwiejsze zastosowanie load balancingu. W specyficznym przypadku API Gateway może być load balancerem.
- Łatwiej zastosować blue/green deployment. Dzięki Gateway’owi po deployu możemy przekierować ruch ze starych do nowych serwisów i staje się to bajecznie proste.
Wady
Jakie mamy minusy tego rozwiązania:
- Jako, że z natury mamy teraz pojedynczy punkt dostępu do systemu, w przypadku niedostępności tego serwisu, cały system staje się niedostępny. Jeżeli mamy problem z wydajnością w API Gatewayu wpływa on w znacznej mierze na cały system.
- Dodajemy następny komponent w systemie
- Minimalnie wydłużony czas względem bezpośredniego zapytania klient-mikroserwis
Miałem to szczęście, że dość szybko zostałem zaznajomiony ze wzorcem API Gateway dzięki czemu uniknąłem problemów, które przedstawiłem w początkowej części artykułu.Myślę, że zestawienie wad i zalet pokazuje tutaj jaki potencjał w nim drzemie zwłaszcza przy rozproszonych systemach.
Bibliografia i inne ciekawe linki: